Towards a Generalized Multimodal Foundation Model
X-Decoder (CVPR 2023)
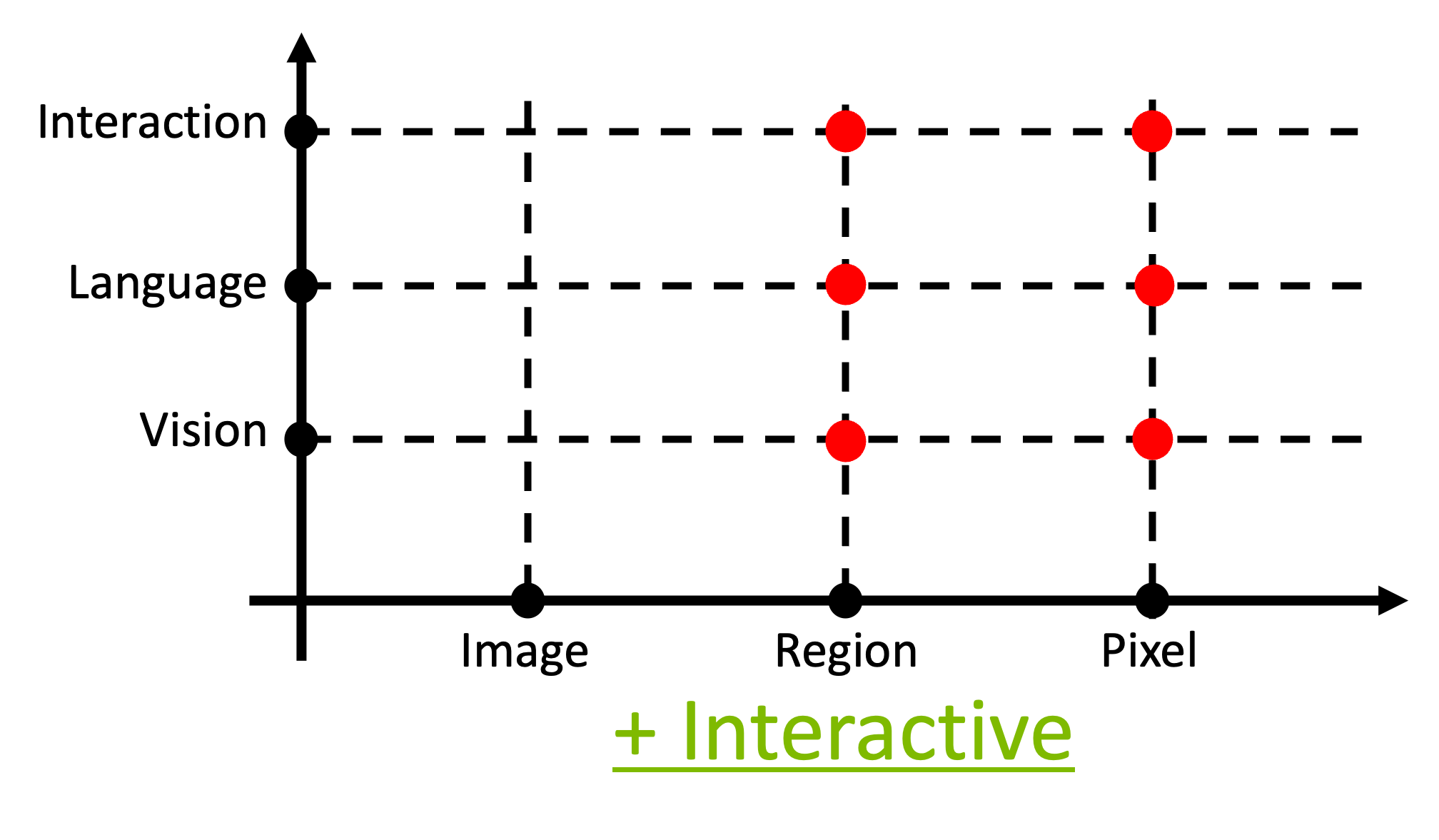
"Generalized Decoding for Pixel, Image, and Language" [1] shortened as X-Decoder is a generalized decoding system that is applicable to various vision-language tasks with a unified architecture. The input and output modalities spans vision-language while the granularity spans pixel-image.
SEEM (NeurIPS 2023)
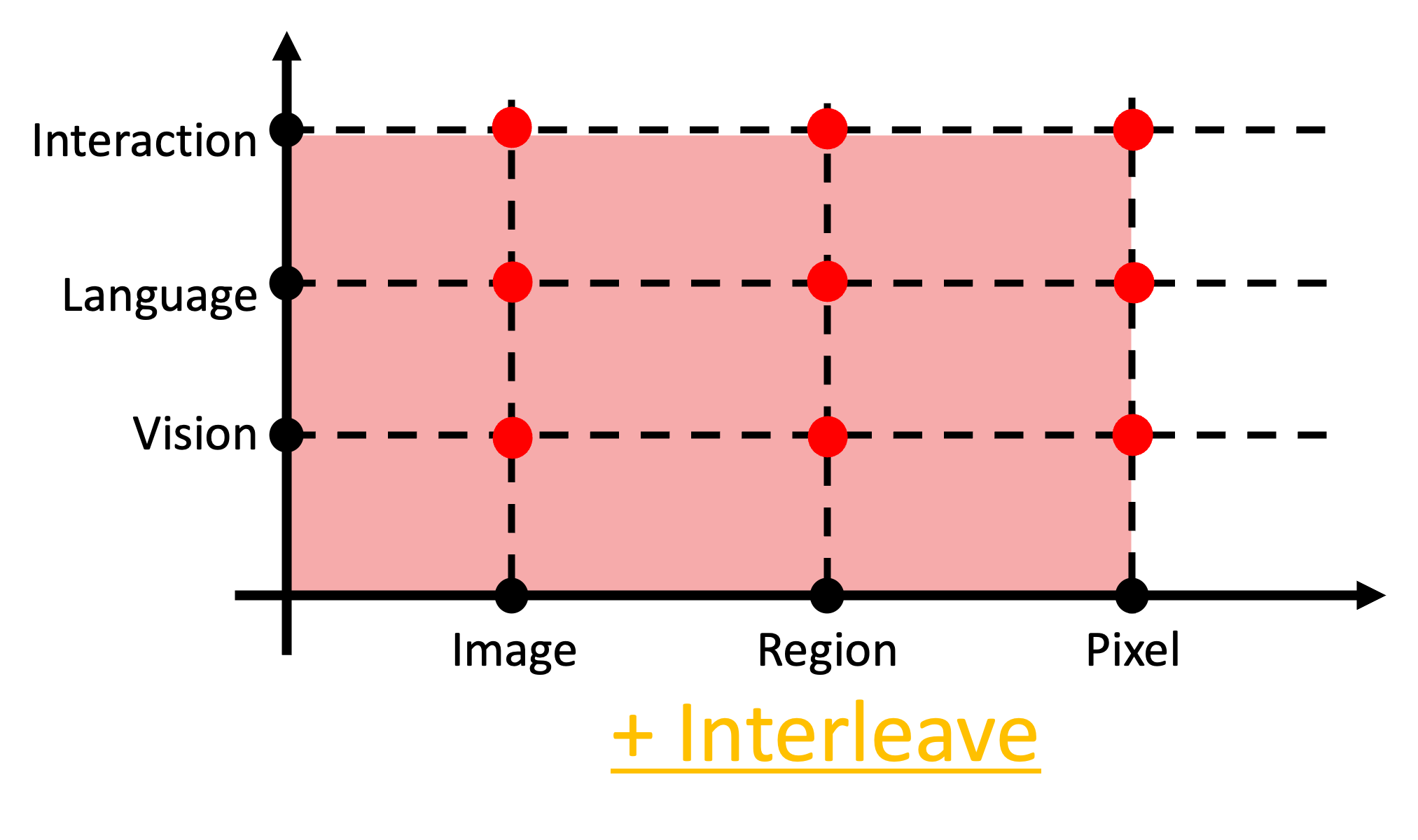
"Segment Everything Everywhere All-at-Once" [2] denoted as SEEM in extending X-Decoder with human interaction capability, where human can refer a segment with scribble, box, point, and etc. Meanwhile, it accepts prompts span vision-language in a composite manner.